
Built in Finland · Private allowlist
Run it anywhere.
Remember everything.
Prove what happened.
One memory across every AI you use, a reviewer from a different family, and a ledger only you own.
One memory across every AI you use, a reviewer from a different family, and a ledger only you own.
Run it anywhere
Your sessions do not have to live on your laptop, holding your keys, stopping when you close the lid. They run in a governed space Spegling operates: walled off from the open internet, reaching only what you allow, holding none of your credentials. When a session needs your mail, it asks the gate. The gate keeps the keys and hands back the result.
A real interactive session, not a one-shot. It keeps working whether you are watching or not, you reach it from any browser including your phone, and every turn seals to the Chain as it happens.
Your laptop, plus a record, minus the laptop.
Spegling is a surface and a substrate. Pick either; the loop runs the same underneath.
Point your AI client at Spegling's MCP server. Your notes, patterns, news, wiki, and tools appear inside Claude Desktop, your IDE agent, or your own code. Setup guide.
{
"mcpServers": {
"spegling": {
"url": "https://api.spegl.ing/mcp/t/<tenant>",
"headers": {
"Authorization": "Bearer sk_…"
}
}
}
}
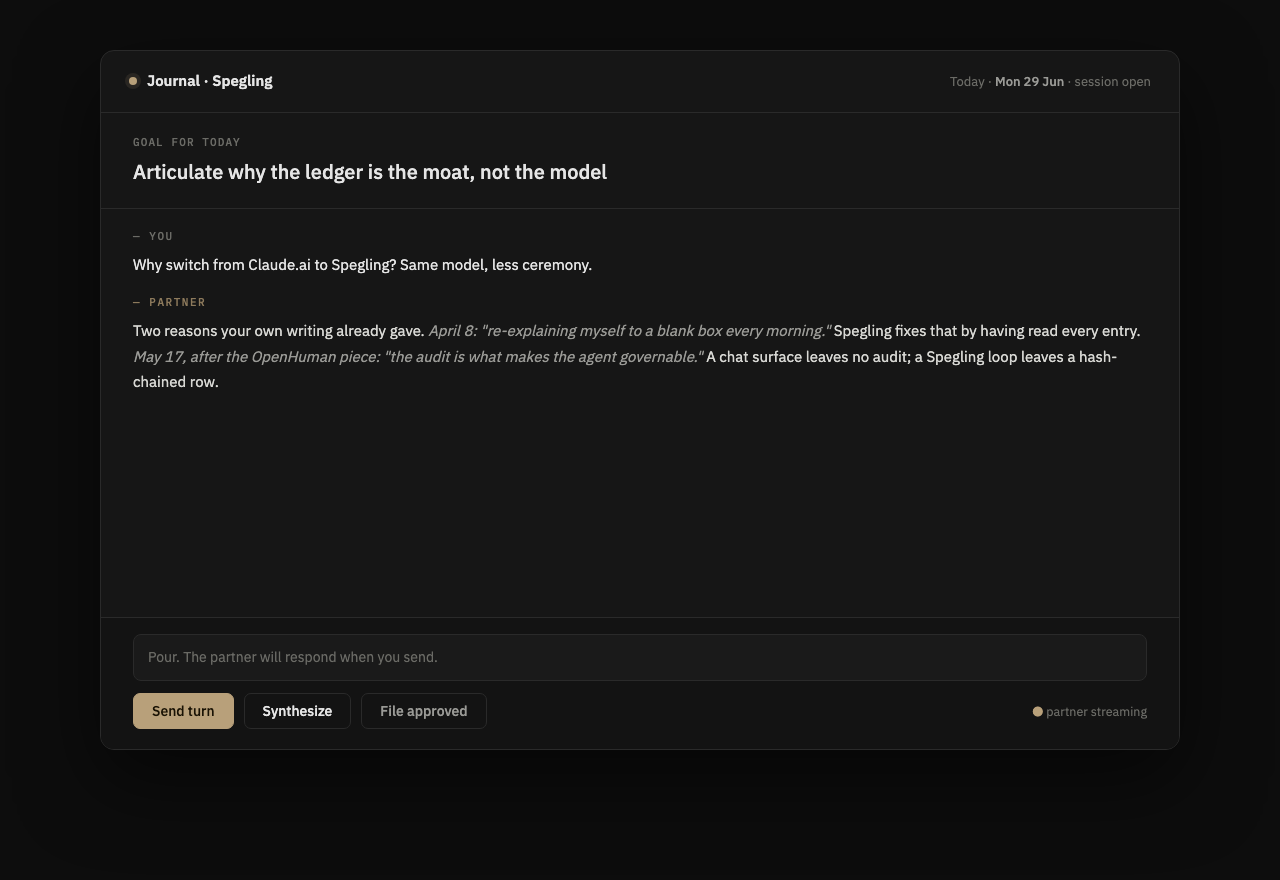
Sign in. The Journal opens. Pour for three minutes; the partner pushes back from your own patterns. File what you keep.
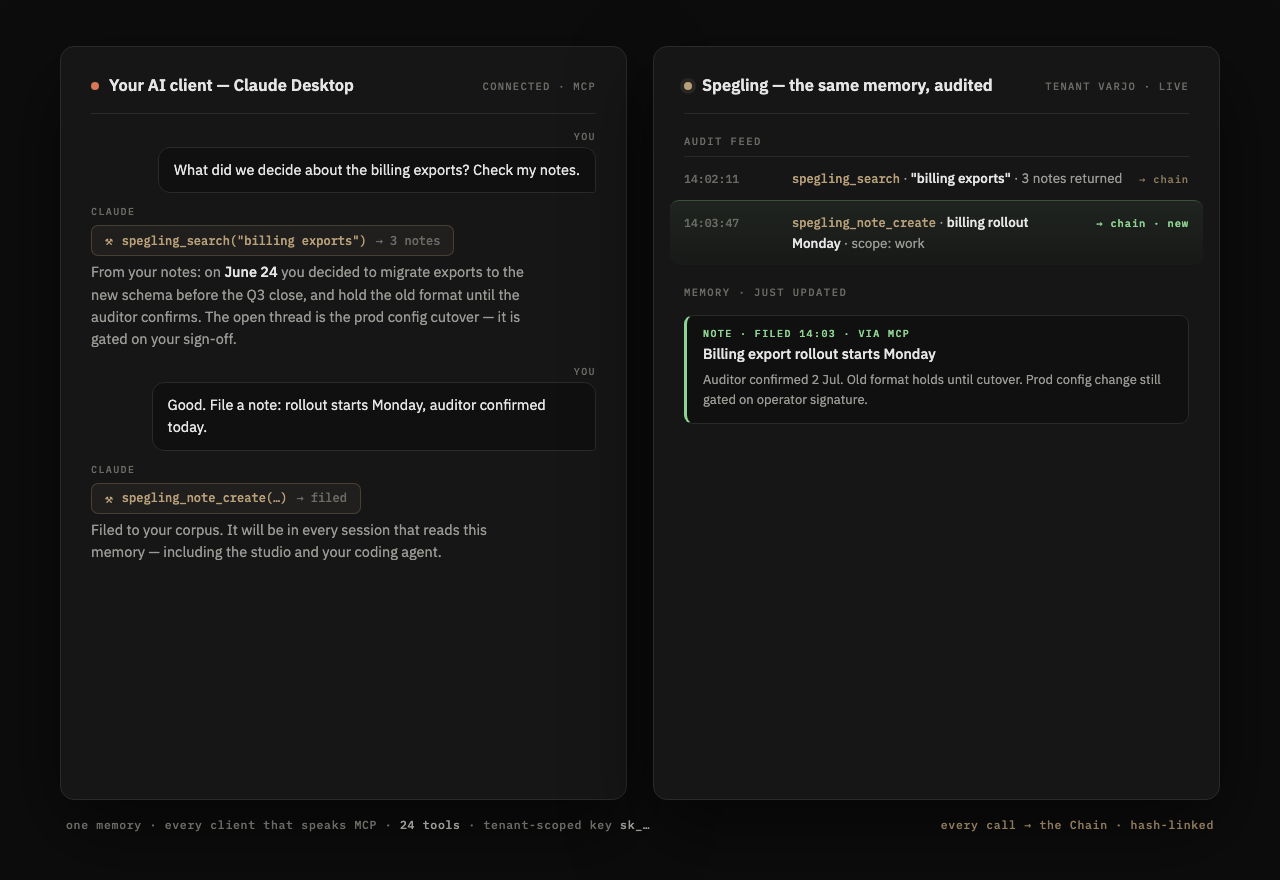
Either way, every call lands as one row on the Chain. A session in Claude Desktop at noon and one in the studio that evening read the same corpus, and tomorrow reads both.
Gmail and Calendar connect to Spegling, not to each AI you happen to use this month.
Tokens live in Spegling's encrypted vault. The calling AI never sees them and cannot leak what it never had. Revoke once, revoked for every client.
The tools are commodities. The boundary is the product.
Read the inbox, draft a reply, check today's calendar: the agent calls a governed capability. Reads and drafts run free; the send stops and waits for you.
Three Gmail accounts, three hats, three ceilings. The founder hat cannot read the board hat's mail. The scope follows who you are being right now.
Nobody adopts a governance tool because policy says so. People come because the useful things live behind the gate: mail, calendar, corpus, search. A week in, the side effects turn out to be the point.
Remember everything
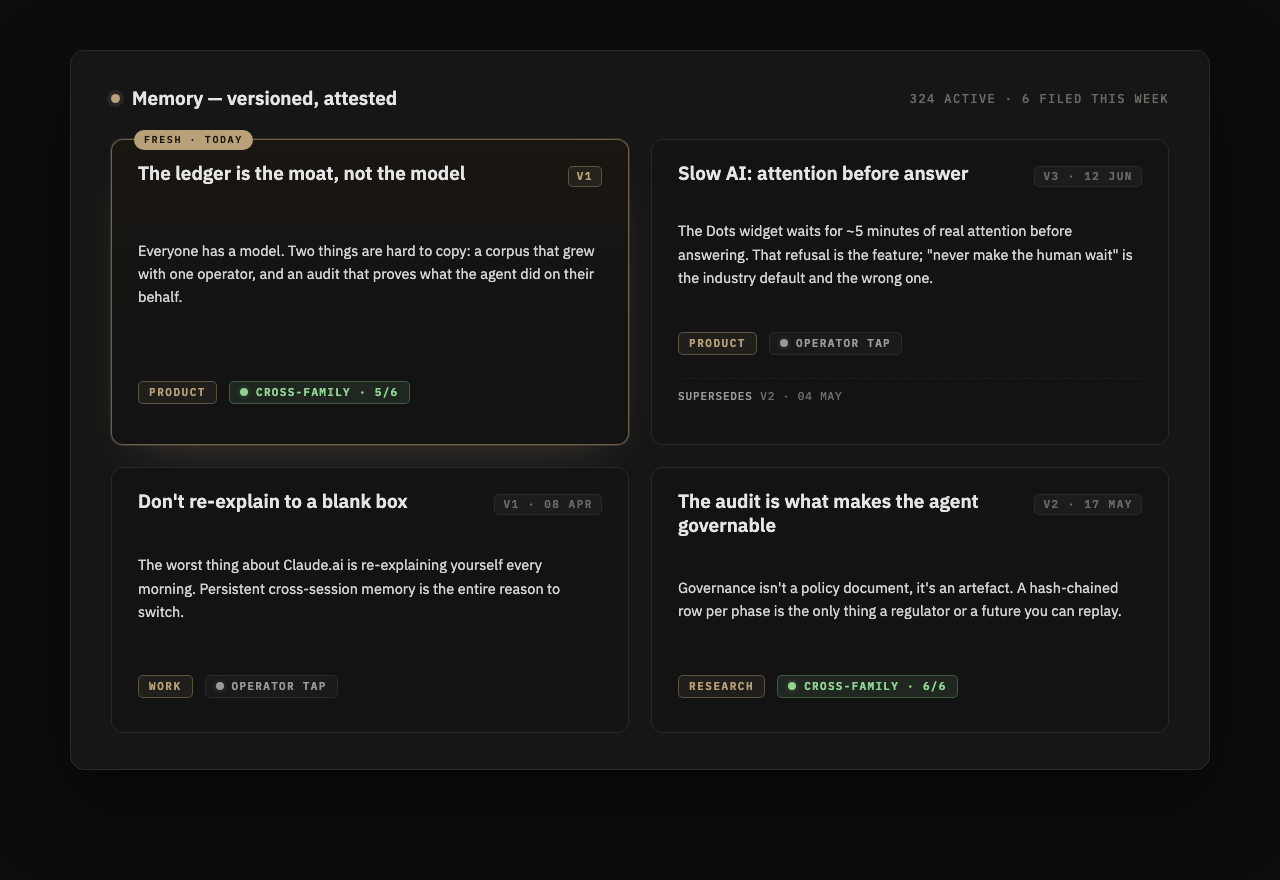
Your notes, your patterns, and every session you have closed. Each carries a version and an attestation. The next session reads from it, so it has to be right.
Promotion takes one of two things: your tap, or a passing cross-family review. That friction is the feature. A memory you can trust is worth more than one that is merely large.
Your work travels in lanes. Founder, advisor, board: three hats, three corpora, three audits, separate by construction. Patterns travel separately too, in plain Markdown you can fork tonight.
Models change. Your history does not.
The current-state snapshot: your inbox right now, what got fetched this morning. It changes all day and that is fine, because none of it counts yet. Nothing crosses into Memory until you save it, and then it crosses with a version like everything else.
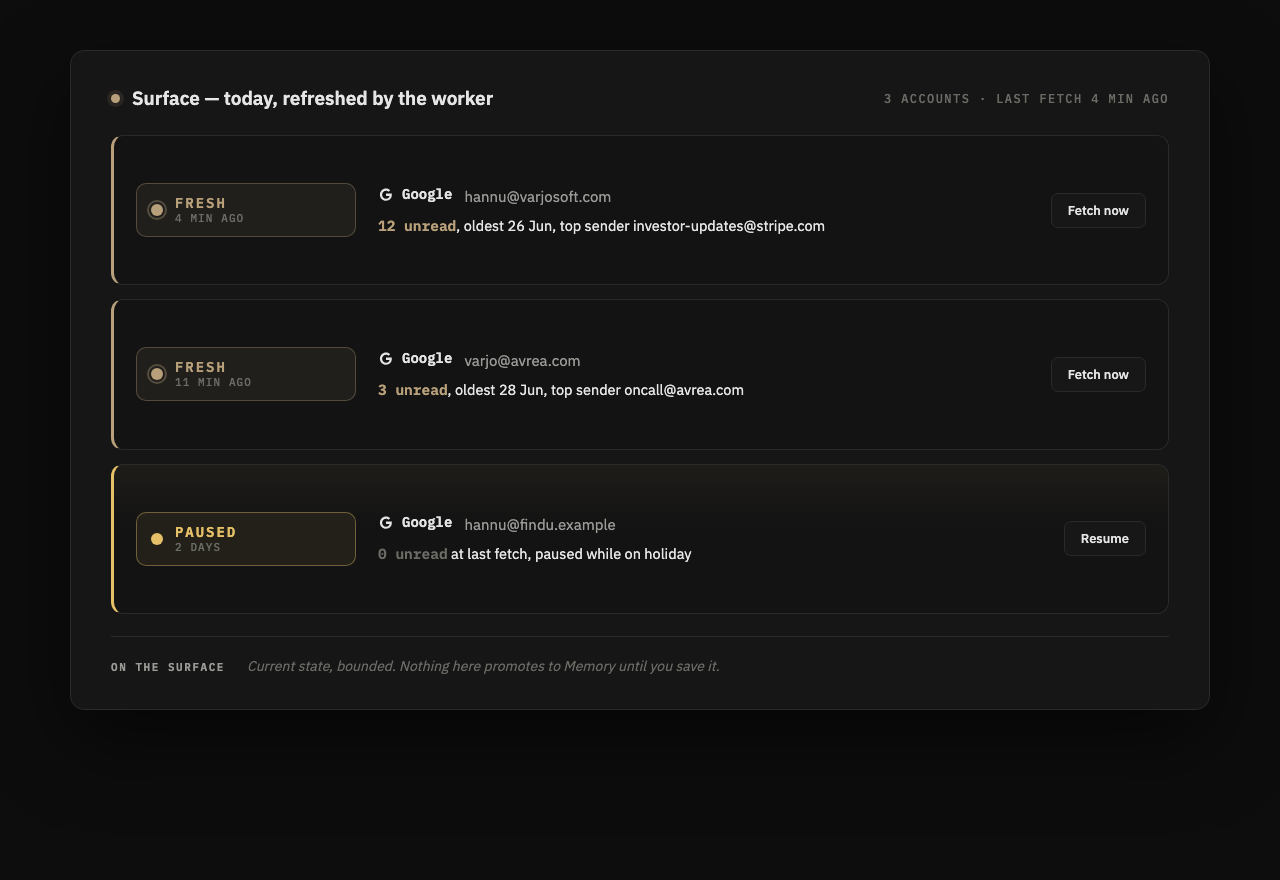
Prove what happened
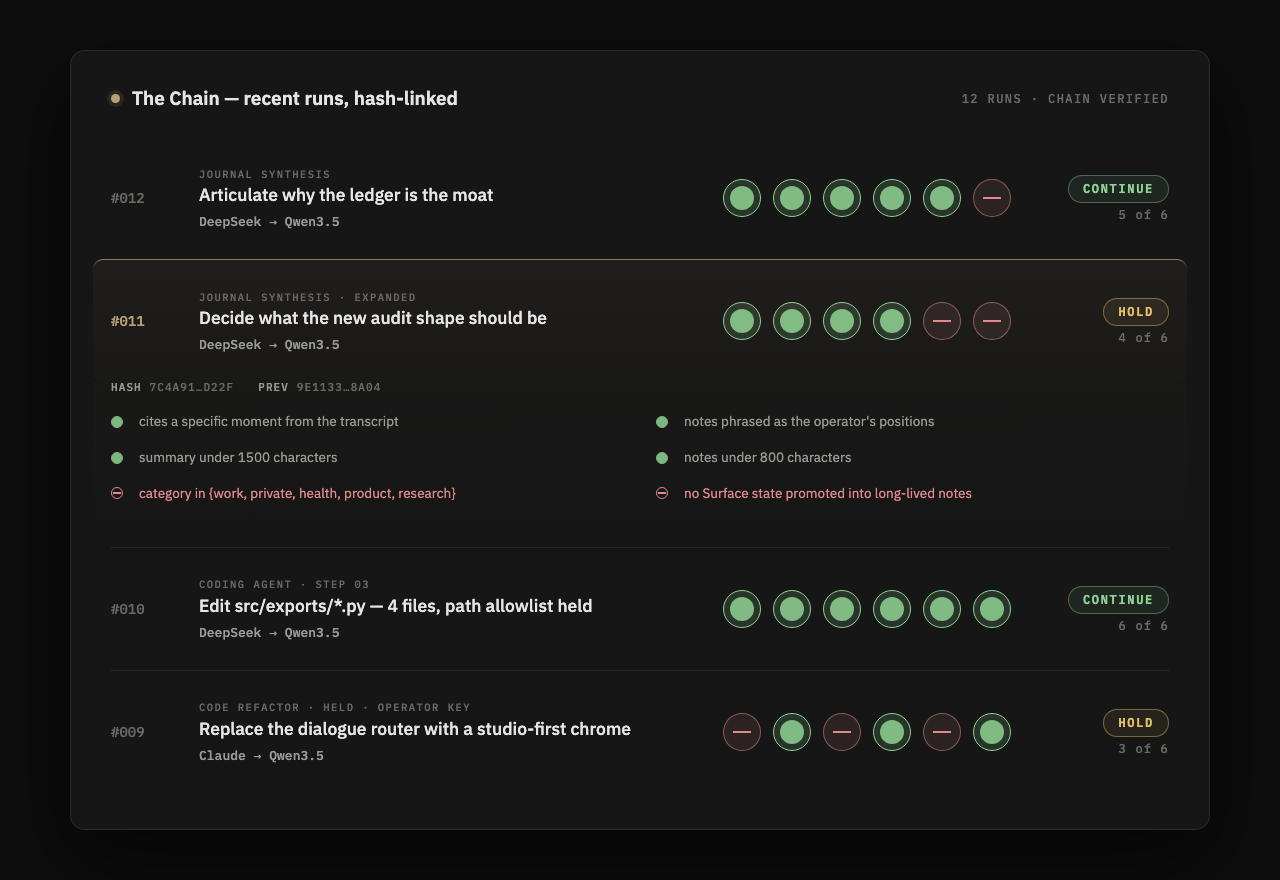
Every governed run lands as one row: the maker's output, the reviewer's verdict on each question, what it cost, and the hash of the row before it. To rewrite one row you would have to rewrite every row after it, and the hashes would tell on you.
It is proof of what a machine did on your behalf, in order, with receipts. Export it whenever you want. It is yours, not a log you rent.
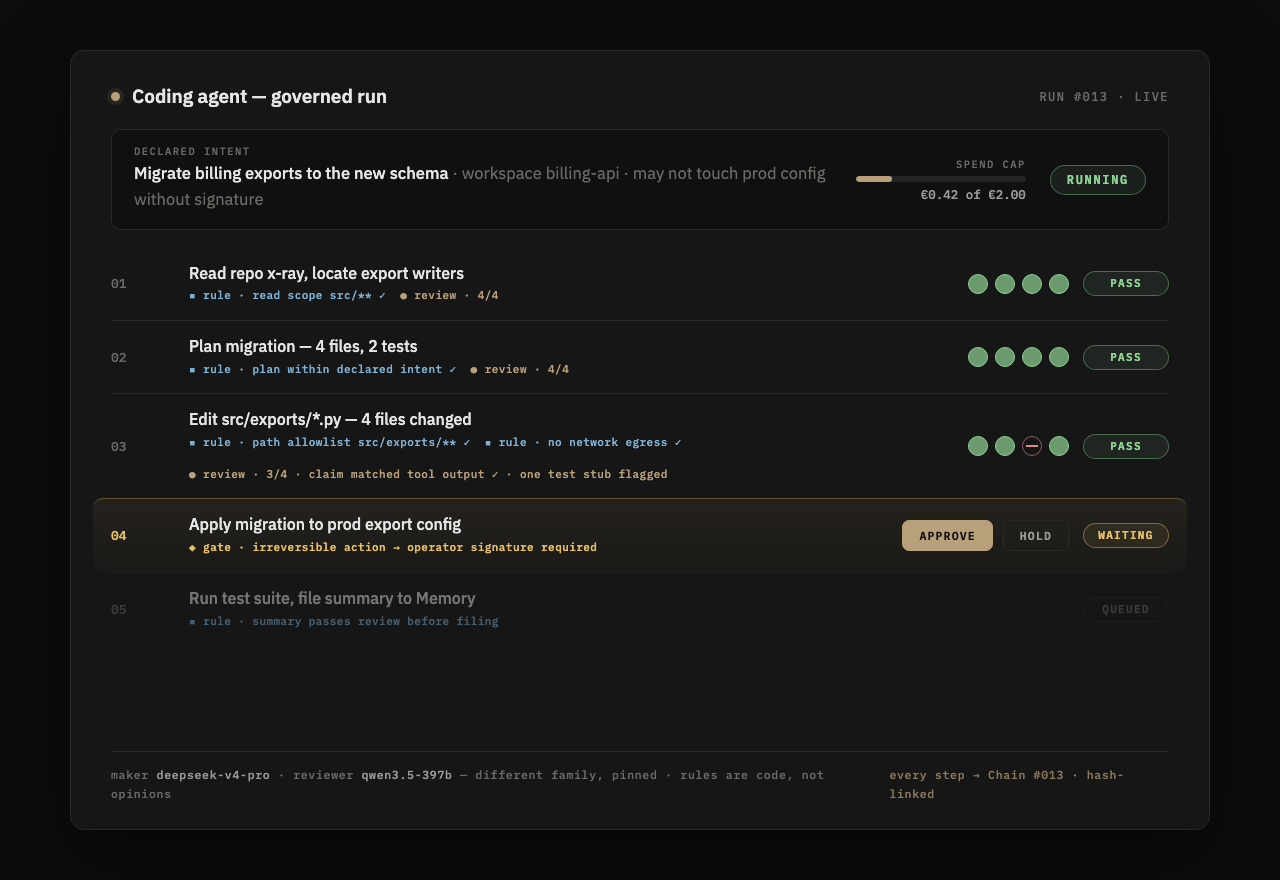
End a session, run an agent step, file a note over MCP: the same loop runs before anything touches your memory.
A maker model does the work: writes the synthesis, edits the files, drafts the reply. Your pick of the roster, DeepSeek on Nebius by default, reading your corpus.
A model from a different family answers a fixed set of yes/no questions. One verdict per question, no vibe-check. You pick the family; the only rule is it cannot be the maker's.
What passes is filed to Memory and appended to the Chain. Each row carries the verdicts, the cost, and the hash of the row before it.
Even the vendors admit the gap. Their own guides prescribe verifier agents and audited progress claims, then ship no ledger you own and no reviewer from outside their own family. Their verifier is another instance of themselves.
Different family is only possible with a roster. Qwen, Kimi, DeepSeek, GLM: open-weight families on Nebius, in the EU. Bring your Claude or GPT key and they join it.
Record everything. Gate what you cannot take back. Half the gate is not a model at all: path allowlists, spend caps and irreversible-action stops are plain code. The stop closes only on what you cannot undo, so it is not the kind of governance teams route around.
You approve what files. The loop checks and shows; it does not decide.
Everyone has a model, and a better one ships every few weeks. Three things here are hard to copy: the model that has read all of you, the gate your tools already live behind, and a ledger that can prove what happened.
The maker and the reviewer come from different model families. A maker grading its own homework is not a check; a different family means the second opinion is not the same blind spot twice.
You hold the key. Walk away, and the data walks with you.
No scores, no summary judgment. Because every check is a yes or a no, a failed review tells you exactly what failed. Vague approval is impossible, and so is vague blame.
Forging one decision means forging every row after it, and the hashes still would not line up. The proof does not depend on trusting Spegling: the exported chain checks itself.
When AI moves into regulated work the questions get concrete: what did the system do, when, and who can check it. The answer the law is settling on is a continuous, traceable record.
Article 12, by construction. The EU AI Act requires high-risk systems to keep a continuous, tamper-evident log across their lifetime. The Chain is that log with no extra work: every run, its verdicts, its cost, hash-linked and exportable. The obligations phase in through 2027 and 2028, which is time to build this in, not a cliff to scramble for.
Article 14, in proportion. The Act asks for oversight “commensurate with the risks, level of autonomy and context of use”, and warns against automation bias. Approval on every step is how you breed it: reviewers stop reading and start clicking. So the record is complete and the stop is proportionate.
It runs in the EU. The default models sit on European infrastructure, under European jurisdiction.
Read the law: Article 12, Record-keeping, Article 14, Human oversight, and Article 50, Transparency of the EU AI Act (Regulation 2024/1689).
A ledger written as the work happens is evidence. The same thing reconstructed after a dispute is testimony worth a fraction of it. You cannot retrofit contemporaneity, which is why the record has to come first.
Spegling is not a certification and does not make you compliant on its own. It produces the record and the independent review your conformity and audit work stand on. The certificate is someone else's to issue; the evidence is what this builds.
Agents write a growing share of working software. Git holds half the story: what changed, line by line. Ask what follows and it goes quiet. Which model wrote this, against what stated intent? Who reviewed it, from which family? What did it cost?
The Chain answers those. A coding run is work like any other: a maker writes the diff, a reviewer from a different family judges it against the intent, and the row seals the verdicts, the cost, and the commit it explains. Every time production has outgrown human witness, a second ledger has appeared beside the production line. Double-entry bookkeeping got the audit. Flight got the recorder. Software is crossing that line now.
We run it on ourselves first. The loop is pointed at Spegling's own repository: agent-written changes bound for cross-family review before they can merge.
The loop is what you demo. The ledger is what you defend.
One goal, one session, one transcript. The partner pushes back the same day. Nothing to set up first.
Surface starts filling on its own, and every AI you use reaches mail through the gate, never holding the keys.
The cross-family review runs, and the proposals you approve cross into Memory with a version.
The session opens already knowing what you decided. You stop re-explaining yourself to a blank box.
A week of runs, each with its verdicts and hash, exportable whenever you want.
The MCP endpoint takes ten minutes and a config block. The studio takes a sign-in. Both land on the same ledger. Access is by invitation while the pilots run: write a line about what you would run through it, and a person answers.
